


This blog post is based on the internal work of Saurabh Gupta, former General Manager , Data Science and Analytics at Michelin India, and is now being published by StackRoute.
The fact is not new that data-driven outcomes have been one of the most electrifying revelations of the 20th century. Almost every organization considers data as the primary driver for their business and growth. Several strategies have evolved to manage the storage, analytics, and consumption of data. Not just for regulatory purposes, but data help to churn out significant business insights. Organizations play smart while chalking out data and analytics strategy by doing a value mapping between investments and business outcomes. This investment could be in building data squads, platforms, data products, or democratization. An efficient data and analytics strategy may start as a general utility and mature into a business enabler or a strategic driver.
“The potential for data-driven business strategies and information products is greater than ever,” says Andrew White, Distinguished VP Analyst, Gartner.
One of the primary challenges of data and analytics strategy is data literacy. Data stewards and evangelists struggle to convince and explain power of data to the business community, and similarly, they also lack the business understanding of their work. Data literacy refers to the ability to communicate business processes through data. Understanding of data sources, methods to curate and transform, business rules, and access methods are obvious aspects of data literacy. Therefore, the starting point of the trajectory could be setting up a layer that holds the organizational data. Data from all heterogeneous source systems may converge to a common platform called data lake. Data lake offers a robust data management strategy to address “big data” challenges and explore business outcomes through data engineering, analytics, and democratization. This article is intended to bring in awareness on key aspects of a data lake, including architectural patterns and operational pillars.
When was the “Date Lakes” term coined?
In the year 2010, James Dixon came up with a “time machine” vision of data. Data lake represents a state of enterprise at any given time. The idea is to store all data in much detailed fashion at one place and enable business analytics applications, predictive and deep learning models with one “time machine” data store. This leads the way to Data-as-an-Asset strategy wherein continuous flow and integration of the data enriches a data lake to be thick, veracious and reliable. By its design and architecture, a data lake plays a key role in unifying data discovery, data science and enterprise BI in an organization.
James Dixon quotes – “If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
What’s the concept behind data lakes?
A data lake stores organizational data flowing from all systems that generate data. In other words, it acts as a single window snapshot of enterprise data in raw format. The data under ingression may or may not hold a relational structure. What this means is that there is no defined schema in a data lake. A data set may be coming from a relational database (like Oracle or MSSQL), or file system as documents, images or videos, or messaging service. From data ingestion to transform to governance and operations, every aspect of data lifecycle gets addressed in a data lake ecosystem. If an organization has little or no footprint of unstructured data, then can even run data lake on relational platforms like Oracle Exadata or Greenplum. In other cases, hadoop platform comes out to be the obvious choice for data lakes. Hadoop not only provides scalability and resiliency, but also lowers down the total cost of ownership.
At a broader level, data lakes can be split into two layers namely, data mirror layer and analytical layer. Data mirror layer holds the as-is copy of the data from source systems. It is built through a conventional batch process (ELT) or a streaming (CDC) process to hold data tables. Once the mirror layer is ready, analytical layer is built on top of mirror layer to feed business applications, operational reports, or any other access points used by the business users. Analytical layer contains data consumption tables which are frequently refreshed using a transformation logic that runs on mirror layer objects at regular intervals.
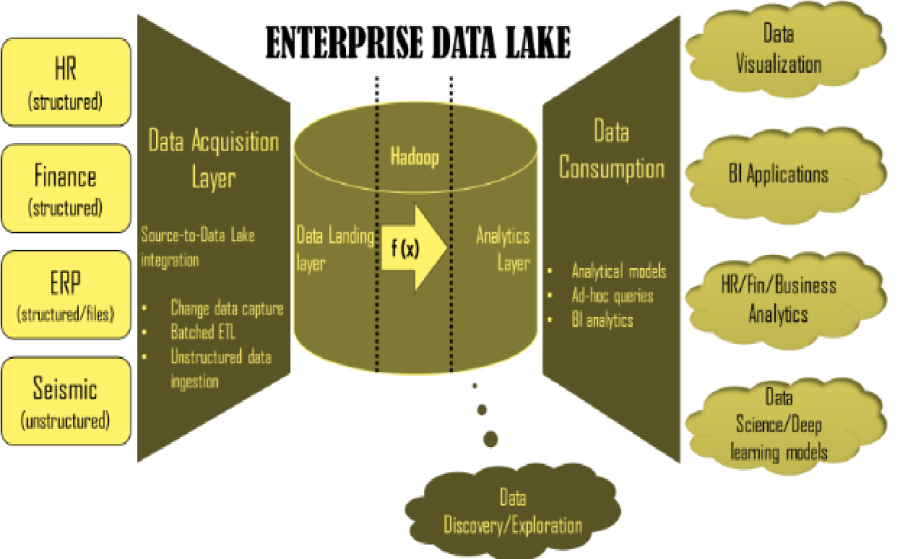
Figure (a). Enterprise Data Lake Architecture
From the above architecture diagram, there will be multiple data source systems dumping data into the mirror layer of Enterprise Data Lake. Source systems may differ in data format, structure, concurrency, growth rate. Without hampering the structure of data from the source and without investing efforts into data modeling in Hadoop, all source system data gets ingested into data lake at stipulated frequency.
Top 5 design characteristics of Date Lake:
Let us understand key characteristics of an enterprise data lake –
-
Data lake architectural patterns
-
Inflow data lake – This architectural pattern focuses to build a “Data Hub” to bridge information silos to discover new insights. In relational world, it resonates well with a data warehouse and data mart approach. Users can extract the data of interest through SQL queries.
-
Outflow data lake – An outflow data lake caters to the data needs at a rapid scale under agile governance. Business focus is the key here as the organizational data staged within a single repository can be constructively transformed to feed customer facing applications. The method of data extraction can vary from SQL to REST APIs to data libraries.
-
Analytics as a Service – This architectural pattern attempts to build an analytics lab where users from disparate backgrounds can be on-boarded to fulfill data needs, that too with minimal governance. An outflow data lake empowered with analytics could mature into an Analytics-As-a-Service ecosystem. Given an instance, a data analyst can run SQL queries to pull data which he needs, or a data scientist can use R and Python libraries to pull data for his analysis. It also allows running complex and sophisticated machine learning models to run in embedded fashion, thereby catering to wider community.
-
-
Data availability
– Data in the lake must be accurate and should be available to all stakeholders and consumers soon after it is ingested.
-
- Extensibility – Unless required, creation of data shards, is not a recommended design within the data lake as it will silo out data for captive use cases.
-
Data life-cycle management
– It is an important aspect of data strategy from maintenance and governance standpoint.
-
- Archival strategy – as part of ILM strategy (Information Lifecycle Management), data retention policies must be created. Retention factor of data, that resides in a relatively “cold” region of lake, must be given a thought. Not a big deal in hadoop world though, but storage consumption multiplied with new data exploration, brings a lot of wisdom to formulate data archival strategy.
- Data disposition – Data lake serves as the single window for organizational data needs, therefore, data in the lake can be archived, but not be deleted.
-
Data governance council
-
Data governance policies must not enforce constraints on data – data governance intends to control the level of democracy within the data lake. Its sole purpose of existence is to maintain quality level through audits, compliance, and timely checks. Data flow, either by its size or quality, must not be constrained through governance norms.
-
Data reconciliation strategy– From the data operations perspective, data reconciliation is a critical facet of quality.
-
-
Data lake security
– Data architects can start with a reactive approach and strive for proactive techniques to detect vulnerabilities in the system. Data models within the lake should be risk classification as defined by the organization and should be assessed by the governance council.
What’s the difference between Data Lake and Data warehouse?
Data warehousing has been a traditional approach of consolidating data from multiple source systems and ingest into one large data store that would serve as the source for analytical and business intelligence reporting. The concept of data warehousing resolved the problems of data heterogeneity and low-level integration.
Data lake, on the other hand, ingests all data in its raw format; unprocessed and untouched to build a huge data store. Data warehousing strategy relies on data extraction from the source systems and then passing it through a transformation layer before settling down in different schemas (schema on-write). All data in a warehouse is processed, well modeled, and structured. Data warehouse targets business professionals, management staffs and business analysts who expect structured operational reporting at the end of the day. On contrary, data lake opens a war room for data scientists, analysts and data engineering specialists from multiple domains for data crunching, exploration, and refining.
By no means, the differentiation is on the consumption of data or the visualization, but it’s the placement of transformation layer that makes the difference. A data warehouse follows a pre-built static structure to model source data. Any changes at the structural and configuration level must go through a business review process and impact analysis. Data lakes are more agile compared to data warehouse. Consumers of data lake are not constant; therefore, schema and modeling lie at the liberty of analysts and scientists.
One of the factors that differentiate data warehousing and data lake is the ingestion approach. Data warehouse, as we know, follows ETL way to load OLAP objects. Contrary to the traditional ETL approach, data lake ingestion strategy adopts ELT approach. With this approach, data gets loaded directly into data lake mirror layer.

Figure (b) Data agility reduces in a typical ETL process, but remains intact in a typical ELT process
Data lake is ideated to hold data from variety of sources in its rawest format – structured or unstructured. However, having a layer to transform data is not suggestible as it may restrict surface area of data exploration; thereby reducing the data agility. Other rationale behind ELT approach is the performance factor. Running transformation logic on huge volumes of data may foster a latency between data source and data lake. Data transformation can rather be placed at curated layer or consumption layer to process data sets of interest.
Beware of Data swamps!
Data lake follows an ordered way of bringing in the data. It strikes ‘one-for-all’ approach to formulate its data ingestion strategy, data engineering and organization, and architecture. Data governance council reviews the data patterns and practices from time to time and ensures that data lake follows secure, steady and sustainable approaches. A methodological approach to soak in all complexities (data sources, types, conversion) under a common layer is vital for successful data lake operations.
Data swamp, on the other hand, presents the devil side of a lake. A data lake in a state of anarchy is nothing but turns into a data swamp. It lacks stable data governance practices, lacks metadata management, and plays weak on ingestion framework. Uncontrolled and untracked access to source data may produce duplicate copies of data and impose pressure on storage systems. Figure (c) shows key differences between data lake and data swamp –

Figure (c) – Comparison between data lake and data swamp
To prevent data swamp situation, enterprises can adopt best practices listed as below –
-
Advocate data governance – Data governance ensures appropriate sponsorship of all resident data and tags data initiatives with visible business outcomes. Looks after security aspects and participates in capacity planning of data lake.
-
Build and maintain metadata – Metadata management should be encouraged to ease data access and support qualitative data search.
-
Prioritize DevOps charter – DevOps keeps the ingestion pipeline intact and shields data complexities under generic framework.
How to achieve Data empowerment?
Data democratization is the concept of diluting data isolation and ensuring that data is seamlessly available to the appropriate takers on time. In addition to data agility and reliability, it lays down a layer of data accessibility that helps in discovering data quickly through custom tools and technologies. The objective is to empower data analysts with swift access to the veracious data set, to enable rapid data analysis and decision making.
Data lake has been an ardent supporter of data democratization. To withstand today’s data driven economy, organizations are bound to work with humongous volumes of data. The data sets exist in different shapes and sizes and may follow different routes of consumption. However, this data is discoverable to only those who are familiar with data lineage.
Non-data practitioners may find it tedious to explore and play with data of interest. Half of their time wastes in data discovery, data cleansing, and hunting down reliable sources of data. Data sets, dwelling in silos is one of the cruelest factors that prevents liberation of data to its full potential.
Let us discuss few of the approaches –
-
Curated data layers – Curated data layers helps in flattening out data models for functional users. These users may be interested in only 10% of total raw information but could struggle in narrowing down the data of interest. The objects contained in curated layer are intended to provide sliced and diced data in a flattened-out structure.
-
Self-service platforms – Self-service portals may act as data marketplace wherein a user can traverse through data sets, discover based on functional implications, mold and transform data representations, and download them for his own records. In the back-end, the self-service framework can work through with APIs for data set transformation, data discovery, and extraction.
-
Platforms supporting query federation and query franchising – Logical data warehousing is an approach to build a virtual data layer from multiple data sources. The ability to federate or franchise query portions to connect and pull data from different sources plays vital role in building that virtual data layer.
Conclusion
Per IDC (https://www.idc.com/getdoc.jsp?containerId=prUS41826116), worldwide revenues for big data and business analytics (BDA) will grow from $130.1 billion in 2016 to more than $203 billion in 2020. Data lake is a standard way to build an ecosystem for the realization of big data analytics. What makes data lake a huge success is its ability to contain raw data in its native format on commodity machine and enable variety of data analytics models to consume data through a unified analytical layer. While the data lake remains highly agile and data-centric, data governance council governs the data privacy norms, data exchange policies, and ensures quality and reliability of data lake.
About the Author:
Saurabh Gupta
Saurav is a technology leader, published author, data enthusiast and General Manager , Data Science and Analytics at Michelin India. He is the co-author of "Practical Enterprise Data Lake Insights" for Apress publishing in 2018. Earlier, he worked with Packt to author "Advanced Oracle PL/SQL Developer's Guide" in 2016, and "Oracle Advanced PL/SQL Developer Professional Guide" in 2012. He holds management degree from Harvard Business School and Masters from BITS Pilani.
Sources:
Posted on 7 September, 2020

